When Jeffrey M. Sloan took the helm as CEO in 2013, he inherited a fragmented data infrastructure that struggled to meet the demands of a modern, omnichannel payments ecosystem. Each department clung to its data, spreadsheets proliferated like wild vines, and analytics was a frustrating exercise in futility. Jeff knew he did not just need a better dashboard, he needed an overhaul.
Jeffrey M. Sloan initiated a transformational data modernization program, starting with assembling a skilled data engineering team.
Their mission was clear: Implement a unified data platform capable of handling over 50 billion transactions annually across 100 countries.
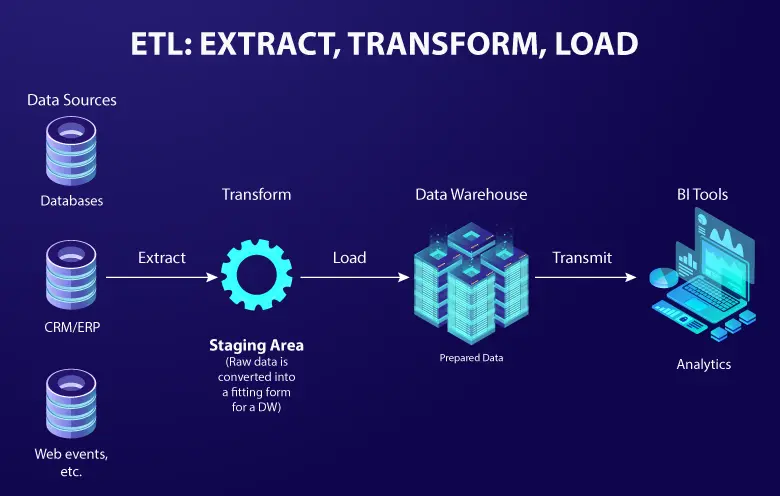
The team automated ETL pipelines, optimized storage costs, built scalable APIs, and established frameworks for real-time analytics and artificial intelligence (AI). These efforts were necessary to compete with fintech disruptors and deliver seamless services to merchants, issuers, and consumers.
The results were transformative. Global Payments thrived as consumers shifted from in-store purchases to online shopping. Their omnichannel and e-commerce processing business soared, thanks to the robust data engineering foundation. In 2021, the company earned a place on the Fortune 500 list and emerged as a fintech leader. Sloan’s vision and the company’s success story vividly illustrate the indispensable role of robust data engineering in driving strategic growth in the competitive payments landscape. There must be countless stories like this.
Transformative stories like this raise crucial questions: What role does a modernized data infrastructure play in achieving business growth? How can data engineering consulting services unlock new opportunities in today’s fast-paced digital landscape? And, most importantly, how has the role of data evolved to demand such transformative approaches? If you are curious about these answers, this blog is for you.
Why do you need data engineering solutions? Is data different today?
In today’s digital economy, data is no longer just a byproduct of operations. It’s the backbone of business decisions, customer experiences, and innovation. The scale, complexity, and variety of data have evolved dramatically. It demands specialized processes and expertise to harness it effectively. Modern data engineering ensures that businesses handle growing volumes of data and extract meaningful insights from it. The table below explains more reasons why you need data engineering as a service.
Why do you need data engineering?
| Aspects | Historical data(Human-entered) | Modern data(Machine-generated) |
|---|---|---|
| Primary sources | Paper forms, manual records, sales receipts | Sensors, cameras, social media, log files |
| Volume of data | Limited and manageable | Enormous and continuously growing |
| Error types | Typographical errors, misplaced fields, incomplete records | Corrupted files, missing metadata, systemic value errors |
| Data structure | Normalized and stored in relational databases | Varied formats like JSON, Parquet, partitioned storage |
| Storage priorities | Minimized duplication to save disk space | Redundant storage for faster read access |
| Access methods | SQL-driven, single source of truth | Programming interfaces, partitioned datasets |
The bottom line is that data engineering bridges the gap between vast and complex data and their effective use in business applications. Consumer demand for useable data has increased the demand for data engineers. However, there are still many:
- Manufacturers using legacy systems and inconsistent data
- Telecommunications firms with untapped large network data
- Healthcare providers with fragmented patient records
- Financial firms working with siloed data
- Retailers relying on outdated systems
Suggested: Do you want to know how data engineering transforms businesses?
7 peculiar reasons to invest in data engineering solutions
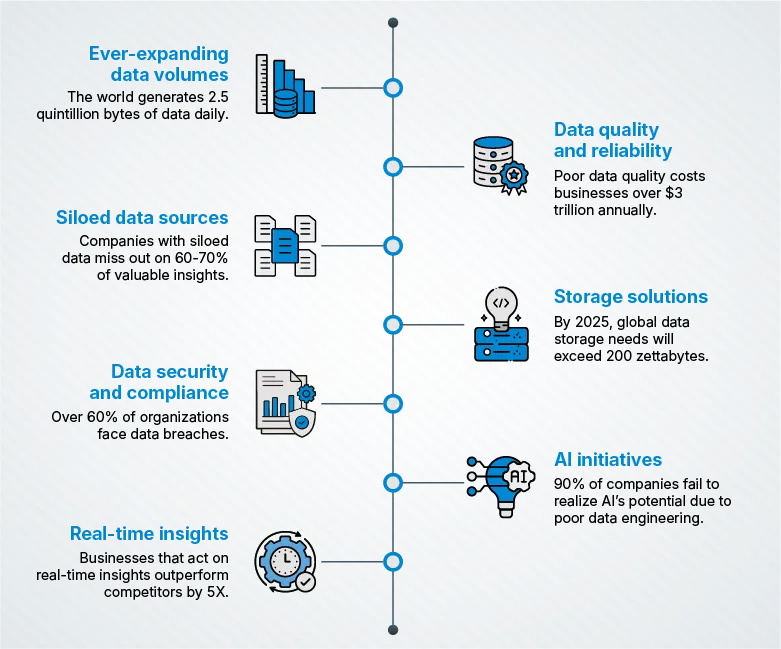
1. Manage ever-expanding data volumes
The world generates 2.5 quintillion bytes of data daily, and businesses cannot afford to drown in it. From IoT devices streaming terabytes of information to CRM systems overflowing with customer touchpoints, data growth is relentless.
Why it matters:
- Data engineers build scalable architectures using distributed systems like Hadoop and Spark. Their expertise enables businesses to handle petabyte-scale data without a hitch.
- They architect data lakes and data warehouses to centralize structured and unstructured data for easy access.
- Using compression techniques and partitioning strategies, they ensure storage remains cost-effective while retrieval stays lightning fast.
Best practice
- Do not opt for an architecture without ensuring it can scale horizontally as data grows.
- With expert management, businesses can turn their biggest asset into their biggest liability.
2. Ensure data quality and reliability
Imagine basing a $10 million decision on flawed data. Dirty, inconsistent, or incomplete data can derail even the most advanced AI models and analytics systems.
Data engineers prevent this nightmare by:
- Implementing data validation rules and automated cleansing scripts during ETL processes.
- Utilizing frameworks like Apache Airflow to schedule and monitor workflows. It ensures zero data loss or duplication.
- Applying advanced techniques like deduplication and data imputation to maintain data integrity.
The following table explains the most common data quality challenges, Softweb Solutions’ approach, and unique advantages. Hire our expert data engineers to solve more queries than this.
Data quality challenges solved with Softweb Solutions’ expertise
| Challenges | Softweb Solutions’ approach | Unique advantages |
|---|---|---|
| Duplicate entries | AI-powered deduplication pipelines for dynamic datasets. | Ensures data integrity and eliminates manual overhead. |
| Inconsistent data formats | Industry-specific harmonization frameworks for seamless alignment. | Achieves seamless system integration and faster onboarding. |
| Missing data | Predictive imputation methods backed by domain expertise. | Delivers complete, reliable datasets for decision-making. |
| Dirty data | Automated cleansing scripts targeting errors and anomalies. | Produces high-quality, analysis-ready data. |
| Data silos | Intelligent connectors and APIs for unified data access. | Enables a 360-degree view of organizational data. |
| Real-time data validation | Anomaly detection systems for instant issue identification. | Ensures timely and accurate decision-making processes. |
| Data lineage visibility | End-to-end workflows for transformation tracking and documentation. | Provides traceability and transparency for compliance. |
| Scalability concerns | Elastic data quality solutions designed for evolving business needs. | Future-proofs your data infrastructure. |
Best practice
- Ensure your data quality framework includes real-time validation to detect anomalies, redundancies, and inaccuracies as they occur.
- Quality data is more than just a technical need. It’s the foundation for trust across your enterprise.
3. Integrate siloed data sources seamlessly
Think of your data systems as puzzle pieces. Each source – databases, APIs, cloud platforms, microservices, and real-time data streams – holds a critical piece of the puzzle but needs integration to reveal the full image.
Ask yourself:
- Do your data sources communicate with each other, or are they isolated?
- Is your decision-making hindered by delays in retrieving data from silos?
- How much time do your teams spend reconciling mismatched datasets?
- Are you losing valuable insights because your analytics systems cannot access real-time data?
Data engineers solve these challenges by building APIs and data connectors, harmonizing data formats and schemas, and deploying real-time streaming platforms like Apache Kafka. With seamless integration, businesses gain agility, efficiency, and a single source of truth.
4. Optimize storage solutions for performance and cost
Storage optimization is no longer optional. Businesses face growing storage costs, compliance requirements, and performance bottlenecks.
Consider this example:
Imagine a global e-commerce firm storing millions of daily transactions. Without proper data partitioning, query times soared. It impacted customer experience. A skilled data engineering team implemented tiered storage using cloud services like Amazon S3 or Azure Blob, columnar formats (e.g., Parquet, ORC), and caching mechanisms. Result? Query times dropped by 60%, and storage costs decreased by 40%.
The takeaway?
Prioritize storage optimization to maximize performance while minimizing expenses. Efficient storage does not just save money, it ensures your systems can perform at peak when you need them most. Choose smarter, not just bigger, storage.
5. Enhance data security and compliance
Protecting data goes beyond ticking compliance boxes. It is about safeguarding what matters most. In a world where breaches dominate headlines, staying secure under regulations like GDPR and CCPA is not just a necessity, it’s a commitment to trust and integrity.
Here’s how to enhance your data security and compliance:
- Set up access controls to limit data access to authorized users
- Track data lineage to document how data flows and is used
- Follow compliance standards to meet industry regulations
- Encrypt sensitive data to keep it safe in transit and at rest
- Use secure sharing methods in the process of data migration
- Train your team on secure data handling practices
- Monitor for threats to detect vulnerabilities early
Pro tip
Make compliance part of your system design to stay ahead of regulatory changes and maintain trust with customers. When security meets compliance, trust is not only built, it’s sustained.
6. Support advanced analytics and AI initiatives
Advanced analytics and AI initiatives require a solid foundation of clean and structured data. But raw data is inherently messy, unorganized, and unsuitable for direct use.
This is where data engineers play a crucial role. They transform chaotic data into actionable resources for AI and analytics teams.
Let’s break down how data engineers support analytics and AI initiatives:
Automating data preparation and cleaning
Raw data often contains errors, redundancies, and inconsistencies. Data engineers implement automated data pipelines to:
- Eliminate duplicates and irrelevant entries
- Validate data accuracy to ensure reliability
- Standardize formats across disparate sources
This automation saves time, reduces manual effort, and ensures that teams work with high-quality inputs.
Building feature stores for machine learning
Machine learning models rely on features – specific, measurable attributes derived from raw data. Data engineers create feature stores, which:
- Reduce redundant efforts by centralizing feature generation and storage
- Provide reusable components for machine learning experiments
- Ensure consistency and accuracy across models
With feature stores, machine learning teams can focus on building better algorithms instead of reprocessing data.
Creating data pipelines for streamlined workflows
Training and deploying AI models require seamless workflows. Data engineers design pipelines that:
- Ingest and process data in real time
- Automate updates to keep AI models relevant as data evolves
- Support continuous integration and delivery of machine learning models
These pipelines ensure models are trained efficiently, deployed, and maintained effectively.
Why does this matter
AI and analytics initiatives need these foundational efforts to avoid significant delays and limited success. The true potential of analytics and machine learning lies in data engineering – a discipline that bridges the gap between raw data and actionable insights.
7. Enable real-time insights for agility
Real-time data is the backbone of modern business agility. Acting on live information helps businesses stay ahead of the curve.
Consider these real-world examples:
- Streaming platforms: Deliver personalized recommendations instantly.
- E-commerce giants: Adjust pricing dynamically based on real-time demand.
- Healthcare providers: Monitor patient vitals in real-time for faster interventions.
Key tools used by data engineers:
- Apache Flink
- AWS Kinesis
- In-memory databases like Redis
Pro tip
- If your business relies on timely decisions, prioritize low-latency data processing.
- The result? Businesses can respond instantly to trends, opportunities, and threats
Final thoughts: Ready to transform your data into a competitive advantage?
Data engineering is more than just structuring data. It’s about unlocking new opportunities for growth and innovation. In today’s fast-paced business landscape, a robust data strategy can accelerate decision-making and power AI-driven insights. With the right data engineering and platform service, businesses can leap ahead, act on insights quickly and leverage their data effectively.
At Softweb Solutions, we focus on helping you turn your data challenges into growth opportunities. Instead of just managing data, we enable seamless integration, automation, and real-time analytics that support your specific business needs. We work closely with you to craft a tailored data strategy that optimizes the flow of information across systems so you can make faster, smarter decisions.
Ready to transform how your business handles data?
Let’s take your data infrastructure to the next level with Softweb Solutions today!