

In this digital age, data has become a priceless asset that fuels innovation, drives decision-making and empowers organizations across various industries. However, the data we receive is often scattered across multiple sources, inconsistent in format and generated at a staggering pace. To derive value from this unstructured data, you need data engineering. The latest innovations in data engineering services are revolutionizing how organizations manage and leverage their data assets.
Data engineering ensures that data is ingested from various sources, cleansed, transformed and organized in such a way that it can be easily accessed and analyzed. By designing and implementing robust data pipelines and storage systems, data engineers enable organizations to handle massive volumes of data, perform complex transformations and extract meaningful insights.
In the world of constant evolution of technology and methodologies, staying ahead of the game in data engineering is crucial. By embracing the latest trends, you can optimize workflows, enhance data processing capabilities and drive innovation in the rapidly evolving data landscape.
How to use data engineering trends to improve business operations
Real-time data streaming and processing:
Traditional batch processing is no longer sufficient for organizations that requiring up-to-the-minute insights. Real-time data streaming and processing enable the ingestion and analysis of data as it is generated. This allows businesses to make faster, data-driven decisions. Technologies like Apache Kafka and Apache Flink have gained popularity for their ability to handle high-velocity data streams and perform real-time analytics.
Using Apache Kafka, you can build real-time streaming data pipelines and applications that adapt to data streams. For instance, if you want to track how people use your website in real-time by collecting user activity data, you can use Kafka. It helps store and manage streaming data while serving the applications that run the data pipeline.

By implementing real-time data streaming and processing solutions, you can unlock opportunities for real-time analytics, fraud detection, predictive maintenance and personalized customer experiences.
Cloud-native data engineering
The adoption of cloud computing has revolutionized the data engineering landscape. Cloud platforms like AWS, Azure and Google Cloud provide a scalable and cost-effective infrastructure for data storage and processing. Cloud-native data engineering leverages cloud services such as data lakes, data warehouses and serverless computing to build robust and flexible data pipelines.
For example, a data engineer could use Amazon Elastic Container Service (ECS) to deploy a containerized data pipeline that uses Kinesis to process and analyze real-time data from a sensor network. The data could then be stored in Redshift for analysis and machine learning models could be built with Amazon SageMaker.
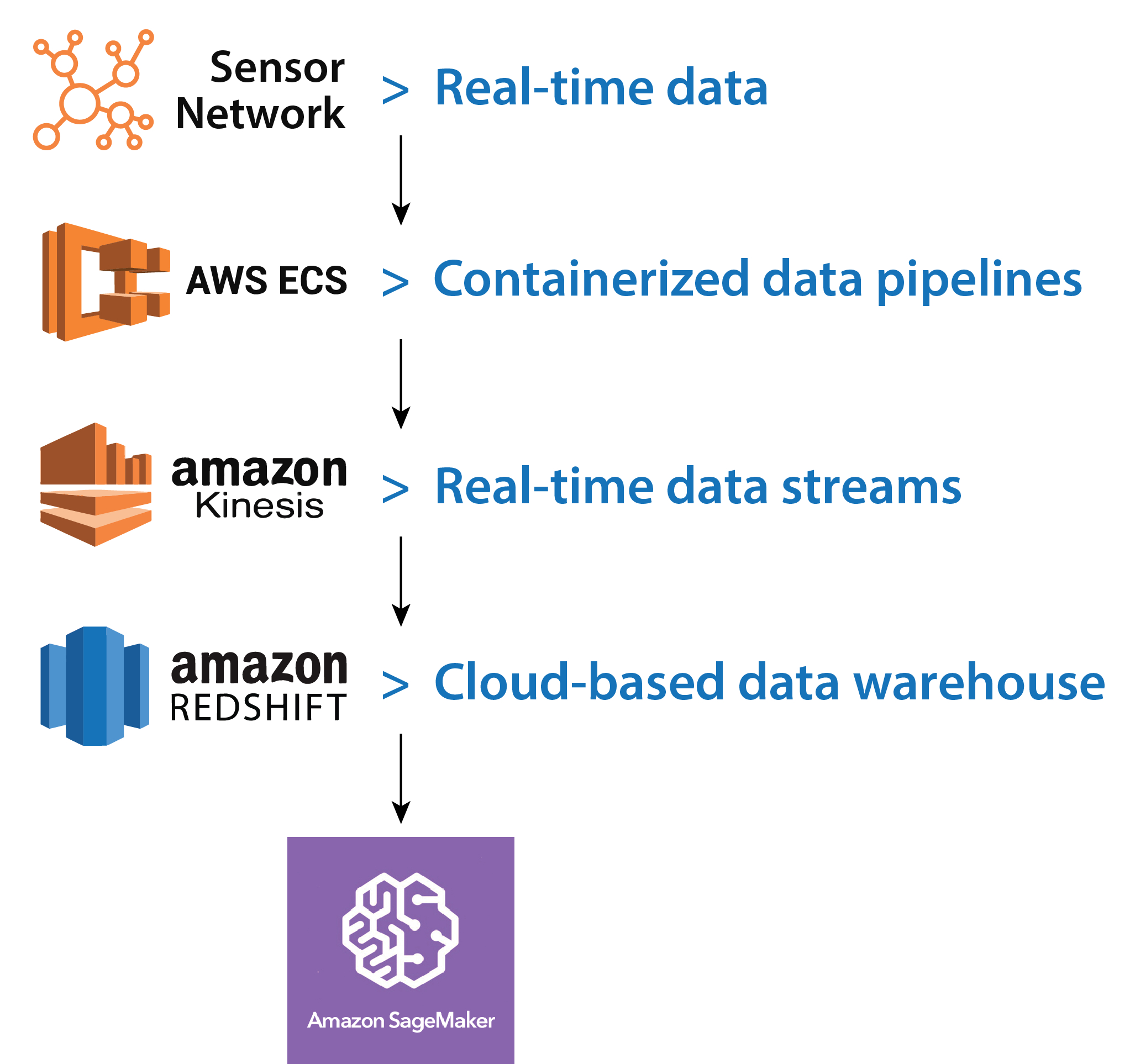
Cloud platforms facilitate collaboration and integration, enabling data engineers to work efficiently and seamlessly with team members. They also connect data pipelines to analytics tools. Cloud-native data engineering offers benefits such as elasticity, scalability and easy integration with other cloud services. It allows organizations to focus on data engineering tasks rather than managing infrastructure, resulting in increased agility and faster time-to-market.
DataOps and Automation
Data engineering operations, or DataOps, is an emerging approach that applies DevOps principles to data engineering workflows. It emphasizes collaboration, automation and continuous delivery of data pipelines. By adopting DataOps practices, organizations can streamline their data engineering processes, improve data quality and reduce time-to-insights.
Automation plays a crucial role in DataOps by eliminating manual, repetitive tasks. Workflow orchestration tools like Apache Airflow and cloud-native services like AWS Glue provide automation capabilities for data pipeline management. Automated testing, monitoring and data engineering workflow reliability and efficiency. .
DataOps and automation work together to improve the efficiency and scalability of data engineering. You can automate data validation and testing using tools like Apache Airflow or Jenkins, ensuring continuous monitoring and adherence to predefined standards. Automation also simplifies data transformation and integration through workflows or pipelines by using ETL tools such as Apache Spark or AWS Glue. For example, you could use Apache Airflow to automate the process of loading data from a variety of sources into a data warehouse and then use Apache Spark to transform the data into a format that is suitable for analysis.
Machine learning and data engineering
The integration of machine learning (ML) with data engineering is transforming how organizations derive insights from data. Data engineers play a vital role in building robust ML pipelines that collect, preprocess and transform data for training ML models. They collaborate with data scientists to deploy these models into production and ensure scalability and reliability.
Incorporating ML in data engineering allows organizations to automate processes, make accurate predictions and gain valuable insights from complex data sets. Techniques like feature engineering, model serving and monitoring are becoming integral parts of data engineering workflows.
By using machine learning, data engineers can derive insights from data that would be difficult or impossible to identify manually. This can help businesses make better decisions and improve their operations.
For example, a data engineer could use machine learning to forecast demand for products or services. This information could then be used to optimize inventory levels and improve customer service.
Data governance and Privacy
With the increasing volume and sensitivity of data, organizations are placing greater emphasis on data governance and privacy. Data engineers are responsible for implementing data governance frameworks, ensuring compliance with regulations like the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) and protecting data privacy.
Technologies like data cataloging, metadata management and data lineage tools enable organizations to track, govern and secure their data assets. By prioritizing data governance and privacy, organizations can build trust with their customers, mitigate risks and maintain regulatory compliance.
The rise of data engineering in cloud computing has made it easier for organizations to collect, store and analyze data. However, it has also made it more challenging to ensure that data is governed and protected. Data governance can help organizations implement security measures in the cloud and ensure that data is only shared with authorized users.
Here are some of the data governance and privacy practices that data engineers can implement:
- Define data governance policies and procedures: Establish roles, responsibilities, data quality standards, security measures and data retention policies.
- Implement data cataloging and metadata management: Track data assets, ensure compliance and ethics and maintain a central repository of data information.
- Implement data lineage: Track data flow within the organization to identify compliance risks.
- Use data encryption: Scramble data to prevent unauthorized access and protect sensitive information.
- Educate stakeholders: Provide training on data governance, privacy policies and procedures to ensure understanding of roles and responsibilities in data protection.
Data engineering as a service
Data engineering as a service (DEaaS) is an emerging trend that allows organizations to outsource their data engineering needs to specialized service providers. DEaaS providers offer expertise in designing, building and maintaining data pipelines, allowing organizations to focus on their core business objectives. DEaaS can be a valuable tool for businesses that do not have the in-house resources to build and manage their own data pipelines.
DEaaS can be a valuable tool for businesses that do not have the in-house resources to build and manage their own data pipelines. DEaaS providers can help businesses to:
- Collect data from a variety of sources
- Store data in a secure and scalable manner
- Process data in a timely and accurate manner
- Analyze data to gain insights
DEaaS can also help businesses save time and money. By outsourcing their data engineering needs to a DEaaS provider, businesses can focus on their core competencies and avoid the costs of hiring and training in-house data engineers.
DEaaS provides scalability, cost-efficiency and access to skilled data engineering professionals. It eliminates the need for organizations to invest in infrastructure and hire dedicated data engineering teams. This makes it an attractive option for startups and small to medium-sized enterprises.
Turn challenges into opportunities with data engineering
Data engineering is an essential process that involves collecting, storing and processing vast amounts of data. It empowers organizations to enhance decision-making, boost operational efficiency and foster innovation. Let’s explore some specific examples of how data engineering benefits various companies:
Have you ever wondered how Netflix suggests movies and TV shows tailored to your preferences? Thanks to data engineering! By analyzing user data, Netflix personalizes its recommendations, keeping you engaged and satisfied.
Now, as an Amazon shopper, have you noticed how they always seem to have the right products in stock and deliver them promptly? Data engineering plays a key role in optimizing their supply chain. By analyzing customer demand data, Amazon ensures efficient inventory management, reduces costs and enhances customer satisfaction.
These examples highlight the significant impact of data engineering in the real world, enabling companies to provide personalized services, optimize operations and improve customer experiences. As data continues to grow in volume and complexity, the latest innovations in data engineering services will remain crucial for organizations seeking to stay competitive and thrive in today’s data-driven landscape.






